
redis-sentinel
Redis Sentinel为Redis提供了高可用解决方案。实际上这意味着使用Sentinel可以部署一套Redis,在没有人为干预的情况下去应付各种各样的失败事件。
Redis Sentinel同时提供了一些其他的功能,例如:监控、通知、并为client提供配置。
下面是Sentinel的功能列表:
- 监控(Monitoring):Sentinel不断的去检查你的主从实例是否按照预期在工作。
- 通知(Notification):Sentinel可以通过一个api来通知系统管理员或者另外的应用程序,被监控的Redis实例有一些问题。
- 自动故障转移(Automatic failover):如果一个主节点没有按照预期工作,Sentinel会开始故障转移过程,把一个从节点提升为主节点,并重新配置其他的从节点使用新的主节点,使用Redis服务的应用程序在连接的时候也被通知新的地址。
- 配置提供者(Configuration provider):Sentinel给客户端的服务发现提供来源:对于一个给定的服务,客户端连接到Sentinels来寻找当前主节点的地址。当故障转移发生的时候,Sentinels将报告新的地址。
Sentinel的分布式特性
Redis Sentinel是一个分布式系统,Sentinel运行在有许多Sentinel进程互相合作的环境下,它本身就是这样被设计的。有许多Sentinel进程互相合作的优点如下:
- 当多个Sentinel同意一个master不再可用的时候,就执行故障检测。这明显降低了错误概率。
- 即使并非全部的Sentinel都在工作,Sentinel也可以正常工作,这种特性,让系统非常的健康。
- 所有的Sentinels,Redis实例,连接到Sentinel和Redis的客户端,本身就是一个有着特殊性质的大型分布式系统。在这篇文章中,我将逐步地介绍这些概念,最开始是一些基本的信息来理解Sentinel的基本属性,后面是更复杂的信息来理解Sentinel是怎么工作的。
哨兵模式的基本工作流程
redis在运行时会开启一个哨兵进程,主要负责监控实例、选举主实例、通知其他实例新
的主实例的工作。
- 监控实例
判断实例是否正常,主要就是通过哨兵的监控,他会周期性的给所有的实例发送PING命
令,如果实例没有在对应的时间响应,那么哨兵就会把该实例标记为下线状态。如果该实例
为主实例,那么哨兵在把该实例标记为下线状态后,开始进行重新选举主实例的工作。 - 选举主实例
主实例挂了后,会由哨兵进行重新选举主实例的工作,哨兵会根据具体的规则和算法选
择一个健康的从实例作为新的主实例。具体的规则在下文中会提到。 - 通知实例
选举完实例后哨兵会通知其他实例谁是新的主实例。哨兵主要通过将新的主实例的连接
信息发送给其他从实例,在从库中执行replicaof命令以此来成为新主库的从库,并从主库中
进行数据复制。
另外哨兵也会把新的主库的信息同步给客户端,让客户端把新的请求操作发送给新主
库。
判断实例下线
实例的下线状态分为主观下线和客观下线。哨兵会通过PING命令检测所有的实例,没有
响应的实例就会被哨兵标记为主观下线状态。如果该实例为从库,哨兵会直接将他标记为主
观下线。
如果实例为主库,如果是单哨兵模式的情况下,该主库会被哨兵直接标记为主观下线,
然后开始新主库的选举工作。如果是哨兵集群模式,需要多个哨兵一起判断该主库是否无响
应,如果超过一定值的哨兵实例判断该主库为主观下线,那么这个主库就正式被标记为客观
下线,开始进行新主库的选举工作。哨兵集群模式会在下文进行分析。
选举新主库
- 筛选:
选举新主库的第一步会进行筛选操作,主要是为了筛选出正常运行且运行良好的从库,
目的是为了防止选举出来的新主库又由于网络故障等原因导致哨兵又得重新选举新出库的现
象。所以要对这些从库当前的在线状态和之前的网络状态进行筛选。 - 筛选规则:
配置项sentinel.conf中的down-after-milliseconds表示设置的主从库断连的最大连接超时
时间,默认为30秒。
如果在30秒内,主从节点都没通过网络连接和响应并且发生的次数超过了10次,就说明
该从库的网络状况不好,不适合作为新主库。 - 打分:接下来就需要对剩余的从库进行打分,打分的目的是通过规则来选举出分数最高的从库
作为新主库。
- 第一轮打分:配置项slave-priority最高的从库得分最高
通过从库配置的优先级来进行打分,默认都是100,如果有一个从库的优先级最高,那么
该从库就是新的主库了,不需要进行第二轮打分比拼。
如果当前打分都一样,那么进行第二轮打分。 - 第二轮打分:和原主库数据同步进度最接近的从库得分最高
上篇文章提到过主从复制之间存在增量复制缓冲区(repl_backlog_buffer),可以用于当
从库出现闪断恢复后将闪断前的数据恢复到从库的操作。
repl_backlog_buffer是一个环形缓冲区,并且有2个指针表示主库写的位置和从库读的位
置分别是master_repl_offset和slave_repl_offset。
判断从库和原主库同步进度就是通过这两个指针的位置来判断,只有从库的
slave_repl_offset最接近master_repl_offset位置,表示同步进度最接近,得分就最高,获得
最高分数的从库就可以被选举作为新主库。
如果还是存在相同打分情况的从库,那么就会进入下一轮打分选举。 - 第三轮打分:从库id最小的得分最高
第三轮应该属于兜底的选举场景,只有第一轮和第二轮选举时的分数都完全一样时,才
会进入第三轮打分。
通过从库中的id来进行比较,id最小的从库得分最高,就会被选举为新主库。
哨兵模式弊端
哨兵主要的工作在于监控、选举和通知。但是单个哨兵模式也会有一定的弊端和问题,
比如:
- 单个哨兵虽然可以判断主库主管下线,但是否可以减少误判情况?
- 这个哨兵如果挂了,redis的主库选举和切换该如何工作?
因此在实际应用中,我们可以选择哨兵集群的方式来进行部署,多个哨兵之间通过少数
服从多数的原则来进行判断工作。
哨兵集群判断实例下线
上文在第二段”判断实例下线“中提到的主观下线和客观下线。主观下线是指某个哨兵通过
ping的响应超时来判断主实例下线状态,而客观下线是指超过一定数量的哨兵实例都认为主
库已下线,那么该主库就是客观下线状态。而客观下线一般存在哨兵集群中。
哨兵集群如何投票判断主库下线
- 哨兵集群中某一个实例判断主库为主观下线后,就会给其他哨兵实例发送is-master-down-by-addr命令。
- 其他哨兵实例接收到命令后,会根据自己和主库的连接情况作出响应,投出赞成票或
反对票。 - 判断该主库为主观下线的哨兵实例如果获得了一定数值的赞成票,就会将该主库标记
为客观下线。
这里赞成票的阈值可配,可通过sentinel.conf中的quorum配置数量决定。 - 判断主库为客观下线的哨兵会向其他哨兵发送命令,表示由他自己来执行主从切换。
该哨兵想成为执行主从切换的主哨兵,得由其他哨兵赞成才行,并且赞成数量得大于一半的
哨兵数量。 - 如果赞成数量小于一半的哨兵数量,就不会操作主从切换,哨兵集群会等待一段时间
再重新选举主哨兵进行主从切换。
哨兵集群判断实例下线详细工作过程
假设有三个哨兵S1、S2、S3。并且quorun配置数量为2。
- S1判断主库为主观下线状态,向其他哨兵发送is-master-down-by-addr命令,并且其
他哨兵也同意主库为主观下线,S1将主库判断为客观下线开始进行主从切换。 - 同时,S2也判断主库为主观下线状态,并且也向其他哨兵发送is-master-down-by-addr命令,其他哨兵也同意主库为主观下线,S2也将主库判断为客观下线开始进行主从切
换。 - 判断主库为客观下线的S1,想成为主哨兵,向其他哨兵发送命令,表示想成为主哨
兵。 - 判断主库为客观下线的S2,也想成为主哨兵,向其他哨兵发送命令,表示想成为主哨
兵。 - S3收到了S1想成为主哨兵的命令,由于S3没有投过票,所以会返回同意。S2收到了
S1想成为主哨兵的命令,由于S2自己投给了自己,所以会返回不同意。此时S1已经获得了
2票同意票,赞成票大于一半的哨兵数量,可成为主哨兵,进行主从切换。 - 后续S3收到了S2想成为主哨兵的命令,由于S3已经将票投给了S1,所以会返回不同
意。S1也收到了S2想成为主哨兵的命令,由于S1自己投给了自己所以也返回不同意。此时
S2只获得了1票同意票,赞成票小于一半的哨兵数量,不能成为主哨兵。 - 最后,如果S1获得的同意票小于一半的哨兵数量,会导致S1和S2的选举结果不会产
生主哨兵,哨兵集群会等待一段时间再重新选举。
哨兵集群的通信
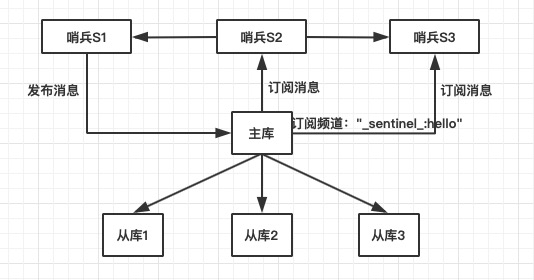
如上图所示,就是哨兵集群的通信机制,主要是通过redis提供的pub/sub机制,即发布/订
阅机制。
哨兵如果想要在主库上发布消息,需要和主库建立连接。从上图中可以看到主库中有一
个订阅频道“sentinel:hello”的频道,不同的哨兵之间就是通过这个默认频道来进行发布/订
阅通讯。
比如,上图中哨兵S2和哨兵S3是如何与S1建立网络连接的,假设S1的ip和端口分别是
192.168.23.01和6379。
- 哨兵S1通过+sentinel sentinel 192.168.23.01:6379命令将自己的ip和端口发布
到“_sentinel_:hello”频道中。 - 哨兵S2和哨兵S3由于已经订阅了该频道,因此可以获取这个订阅消息(+sentinel
sentinel 192.168.23.01:6379),获取到S1的ip和端口。 - 哨兵S2和哨兵S3和哨兵S1建立网络连接。
- 任何一个哨兵可以通过向主库发送INFO命令获得所有主库对应的从库信息,和从库进
行连接并进行监控。 - 其余的哨兵也是根据相同的INFO命令和从库进行连接。
- 至此,哨兵之间组成了集群并进行通信。哨兵也和主从库之间建立了连接并进行监
控。
哨兵和客户端的通信
哨兵不仅需要和主从库之间进行通信,还需要和客户端进行连接通信,因为如果主库宕
机后通过哨兵选举出来的新主库的信息也需要推送给客户端。
哨兵和客户端的通信实际上也是基于发布/订阅机制来进行的。
比如,当哨兵把新主库选举出来后,客户端可以收到switch-master事件(switch-master
就可以使用该事件中的新ip和新端口信息来进行与新主库的通信。
哨兵和客户端通信事件的一些重要频道:
- +sdown(实例进入主观下线状态)
- -sdown(实例退出主观下线状态)
- +odown(实例进入客观下线状态)
- -odown(实例退出客观下线状态)
- +swtich-master(主库地址发生变化)
- +slave-reconf-sent(哨兵发送SLAVEOF命令重新配置从库)
- +slave-reconf-inprog(从库配置了新主库,但尚未同步)
- +slave-reconf-done(从库配置了新主库,和新主库完成同步)
总结
aof和rdb的存在保证了数据的持久性。redis集群模式的存在,是数据可靠的基础保证。
而哨兵模式的存在,是redis高可用的保证,即在主库发生故障时可通过选举和主从切换来
保证redis服务不间断的可用性。
问题一
假设一个redis集群,是一主四从,同时配置了5个哨兵实例的集群,quorum值设为2。在
运行过程中,如果有3个哨兵实例都发生故障了,此时,redis主库如果故障,还能正确地判
断主库客观下线吗?如果可以的话,还能进行主从库自动切换吗?
首先哨兵判断主库客观下线是通过quorum值来进行的,只有认为主库主管下线的哨兵数
量大于等于quorum值时,该哨兵才可以判断主库为客观下线。所以redis主库如果故障,仍
可以正确的判断主库客观下线。
在哨兵集群中想要进行主库切换,需要选举出一个主哨兵来进行主从切换,但是主哨兵
的选举的要求是同意该哨兵为主哨兵的赞成票要大于哨兵数量的一半,由于可运行哨兵只只
有2个了,所以无法选举主哨兵,无法进行主从自动切换
问题二
哨兵实例是不是越多越好?
不一定,哨兵实例越多,虽然可以减少误判率。但是在判断主库客观下线和选举主哨兵
时,该哨兵实例所需要拿到的赞成票也会越来越多,所以总体投票的时间也会增加,导致整
体主从切换的时间变长,导致客户端堆积较多请求操作,导致请求溢出造成请求丢失。
问题三
如果调大down-after-milliseconds值,对减少误判是不是也有好处?
不一定,调大的结果可能会导致实际上已经发生故障的主库,由于值的调大导致哨兵过
了down-after-milliseconds值的时间才能判断出来,反而会影响redis对业务的可用性。